论文链接:https://arxiv.org/pdf/2602.02486
代码链接:https://github.com/microsoft/InfoAgent
摘要
基于 LLM 的深度研究智能体大多构建于 ReAct 框架之上。这种线性设计使得智能体难以重访先前的状态、分支到其他搜索方向或在长时间上下文中保持全局感知,这往往会导致局部最优解、冗余探索和低效搜索。我们提出了 Re-TRAC,一个智能体框架,它通过在每条轨迹之后生成结构化的状态表示来进行跨轨迹探索,该状态表示总结了证据、不确定性、失败和未来计划,并将后续轨迹的生成基于此状态表示。这使得智能体能够进行迭代反思和全局信息规划,从而将研究重新定义为一个渐进的过程。实证结果表明,在 BrowseComp 数据集上,使用前沿 LLM 时,Re-TRAC 的性能始终比 ReAct 高出 15%–20%。对于规模较小的模型,我们引入了 ReTRAC 感知的有监督微调方法,并在类似的规模下实现了最先进的性能。值得注意的是,Re-TRAC 的计算结果表明,随着迭代轮次的增加,工具调用次数和 token 使用量呈单调递减趋势,这表明探索过程逐渐趋于精准,并受到跨轨迹反思的驱动,而非冗余搜索。代码和模型可在 GitHub 链接中获取。
1.Introduction
大语言模型(LLM)已从单轮问答发展到链式推理、函数调用以及复杂的多轮智能体应用。这种演进反映了从被动生成响应到在开放环境中自主、目标导向的问题解决的转变。能够自主搜索开放网络并从数千个网页中收集和分析信息的深度研究智能体(OpenAI, 2025a; Google, 2025)代表了通用智能信息检索的下一个前沿领域。
大多数现有的深度研究智能体都基于 ReAct 范式构建,该范式将大语言模型(LLM)推理步骤与工具调用交错进行,并以线性顺序的方式将两者添加到模型上下文中。本文深入分析了 ReAct 式线性推理工作流的固有局限性。尽管 LLM 推理通过训练可以支持回溯和自我反思等行为,但这种严格的线性智能体工作流并不适合需要广泛探索性调查的开放式任务。重新访问先前的推理状态并分支到其他搜索路径仍然具有挑战性,尤其是在长上下文设置(例如,128K-256K个 token)下,上下文管理和信用分配变得越来越困难。因此,ReAct 框架容易出现局部最优解、冗余探索和低效搜索动态等问题。
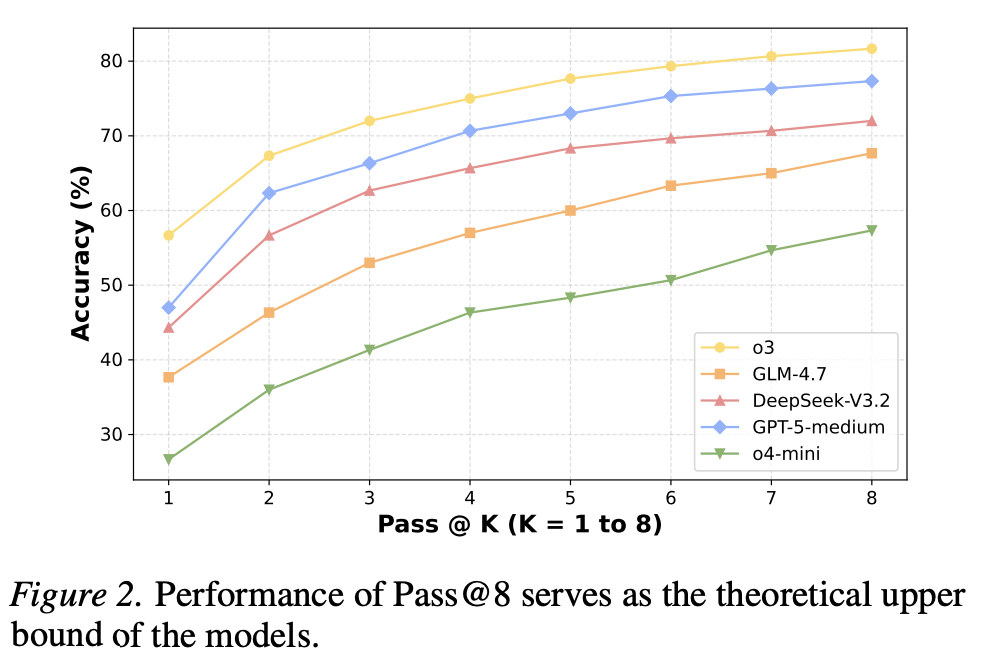
为了赋予基于 LLM 的智能体多样化的探索能力,我们提出显式地引导智能体探索之前未曾探索过的搜索轨迹。这一方向的动机源于两个关键观察。首先,现有的深度研究模型(即使经过大量的强化学习后训练)在 pass@k 任务上的表现也显著高于 pass@1 任务。这种差距表明,重复推理会产生多样化的推理轨迹,这说明模型的局限性通常源于单个轨迹内探索不足,而非推理能力不足。其次,先前的研究表明,LLM通常更擅长验证候选解,而不是从头开始生成候选解,这促使我们采用一种搜索范式,即先广泛生成候选解,然后通过验证进行选择。
我们提出了 Re-TRAC,一个智能体框架,它在每条轨迹的末尾递归地构建结构化状态表示,并将其用作后续轨迹的提示上下文。每个状态表示都概括了调查状态在多个维度上的演变,包括累积的证据、未解决的不确定性、已识别的故障模式以及前瞻性的研究计划。与多个独立运行的轨迹不同,Re-TRAC 支持迭代反思、跨轨迹知识整合和全局信息规划。这种设计将探索从一系列互不关联的尝试转变为一个逐步获得信息的搜索过程。实证研究表明,随着研究的进行,Re-TRAC 智能体发出的工具调用次数和消耗的 token 数量均有所减少,这表明其决策效率更高,并且能够根据先前的经验更有针对性地获取信息。
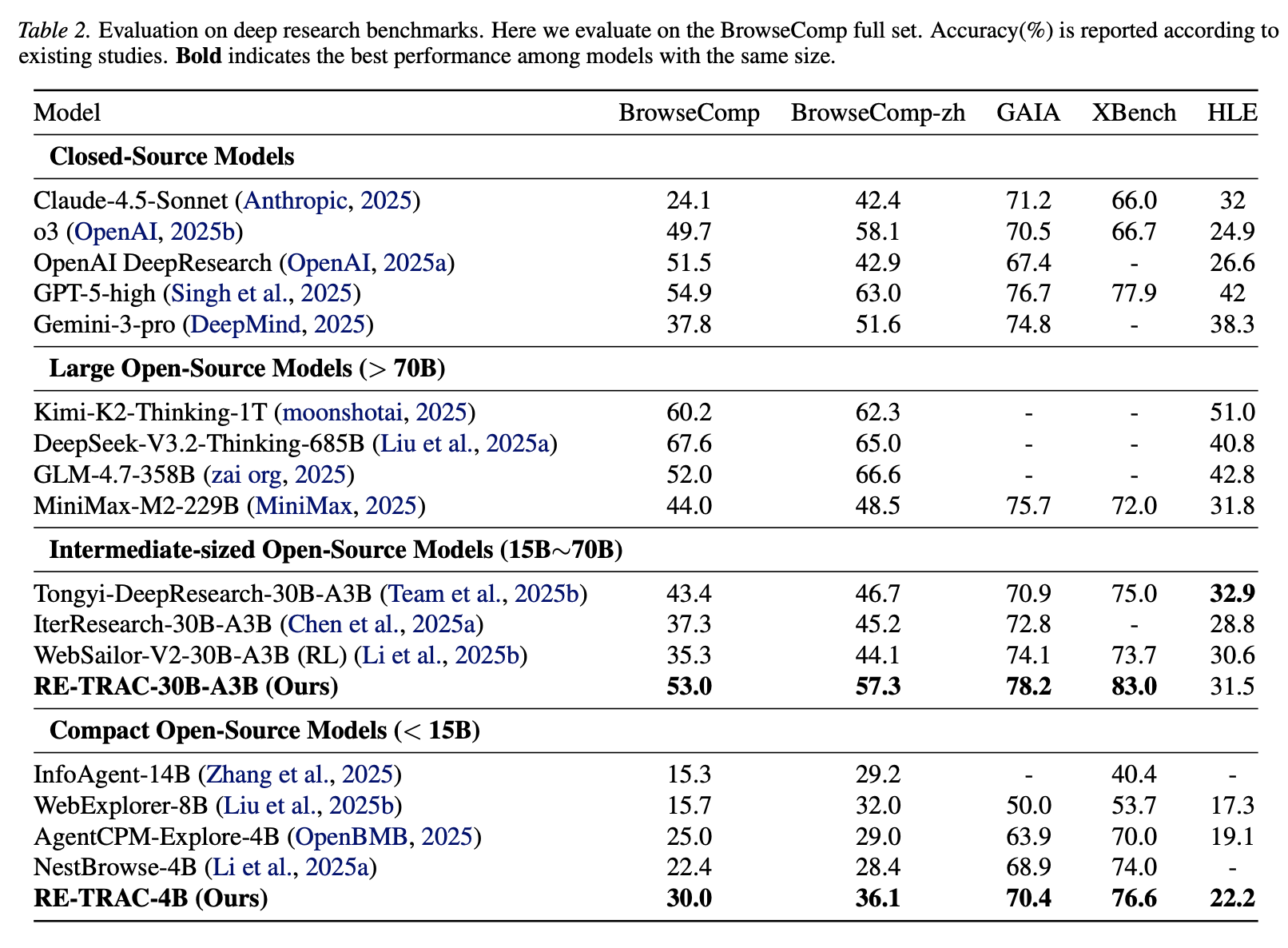
我们的实验表明,当与前沿 LLM 结合使用时,Re-TRAC 在 BrowseComp 基准测试中比 ReAct 的性能提升了15-20%。这激励我们通过 ReTRAC 进一步拓展小型模型的性能极限。为了充分发挥 Re-TRAC 在小型模型上的优势,我们开发了一种后训练优化方案,该方案构建了由显式地基于结构化状态表示的轨迹组成的有监督微调(SFT)数据。这种训练过程教会模型基于结构化的跨轨迹摘要进行推理、规划和工具使用,而不是仅仅依赖于直接上下文。微调后,我们的 30 B 模型在 BrowseComp 测试中达到了 53% 的准确率,而4B模型达到了 30%,在同类模型中取得了目前最先进的性能。
2.相关工作
2.1 Deep Research Agents
深度研究智能体的出现标志着信息检索从简单的系统检索向能够进行长远推理、战略规划和持续工具调用的自主系统转变。由专有模型驱动的智能体,例如 OpenAI Deep Research、Gemini Deep Research、Claude、Perplexity 和 Grok,利用大规模训练和深度工具集成来实现高精度。与此同时,开源模型,包括 DeepSeek、GLM、Kimi、MiniMax 和 Tongyi Deep Research,通过在广泛的智能体任务上进行专门训练,增强了其长远推理能力。此外,InfoAgent、WebSailor 和 DeepDive 等工作探索了数据合成和面向搜索的环境构建等基础性挑战。我们的工作引入了一种递归经验压缩机制,以增强智能体处理长期任务的能力。
2.2 Agentic Context Management
对于执行长上下文任务的智能体而言,有效管理上下文的能力至关重要。近期的研究大致可分为两类:内在上下文优化和用于状态维护的外部记忆机制。对于第一类,许多智能体 LLM,例如 DeepSeek-V3.2 和 GLM-4.7,将上下文剪枝直接集成到智能体的推理循环中,专注于压缩观察空间和剪枝冗余的轨迹历史。与上下文剪枝并行,近期的研究工作侧重于利用外部记忆。IterResearch 和 MemAgent 利用动态记忆结构在每个步骤重建任务状态,丢弃通用历史记录以模拟无限上下文。ReSum 引入了一种“总结与重置”范式,定期将探索历史压缩到紧凑的记忆中。虽然我们的工作自然地将有效上下文长度扩展到无限,但我们的主要目标是批判自身的轨迹,进行自我反思并强化正确的推理路径。
2.3 Test-Time Scaling
传统的扩展法则侧重于增加模型参数和训练数据,而近期的研究范式已转向测试时计算扩展。测试时扩展的主流方法是扩展模型的内部推理过程。诸如思维链(CoT)扩展以及 OpenAI-o3 和 DeepSeek-R1 等推理模型鼓励扩展内部推理路径以分解问题。另一种扩展计算规模的方法是采用集成策略和智能体间验证。自洽性通过采样不同的推理路径并应用多数投票来选择最稳健的答案,从而有效地减少推理错误。多智能体辩论使得不同的 LLM 实例能够相互评判和改进彼此的回答,利用对抗性动态来提高事实准确性并减少幻觉。我们的工作为测试时扩展引入了顺序维度,这与投票或辩论的并行性质有所不同。我们设计了一种新的机制来促进持续的自我反思,使模型能够以高计算效率探索更广泛的可能性。
3.Motivation
通过对深度研究任务中的 LLM 进行系统分析,我们发现了两个阻碍其性能的根本性局限。首先,现有模型探索不足,常常过早地收敛到次优推理路径。虽然鼓励探索的一个简单方法是允许多次尝试(例如,多数投票或 Best-of-N),但这又引入了另一个挑战:信息效率。核心问题在于如何有效地利用这些不同的路径,从而合成出更优的最终输出。
Incomplete Branch Exploration。为了找出当前高级深度研究智能体的瓶颈,我们收集并分析了它们未能输出正确答案的轨迹。分析揭示了一个普遍现象:在大多数失败的轨迹中,存在一些模型计划探索但最终却遗漏的分支。如表1所示,这种情况的比例高达93%。我们将这种普遍存在的探索不足归因于深度研究任务的长期特性与 ReAct 框架固有的线性特性之间存在的根本性结构不匹配。深度研究需要策略性的分支和回溯,而 ReAct 范式将智能体限制在顺序执行路径中,这种差异抑制了模型调整方向或重新评估先前决策的能力。深度研究任务通常需要较长的轨迹,这些轨迹往往跨越数十万个 token,并具有高度密集的相互依赖的工具调用。我们观察到,在线性 ReAct 框架的约束下,随着轨迹的延长,LLM 模型会表现出灾难性的遗忘现象。这主要是因为该模型难以维持长期规划的连贯性。早期阶段制定的关键任务级目标往往会被不断累积的中间工具调用和观测数据所掩盖。

The Potential from Multiple Trials。鼓励探索的一种直接方法是进行多次随机试验。为了量化广泛探索的未开发潜力,我们使用 Pass@K 指标评估了各种 LLM 模型。如图 2 所示,Pass@1 和 Pass@8 性能之间的显著差距表明,当前模型在单次轨迹中无法达到显著的性能上限。
我们的实证观察表明,许多失败并非源于 LLM 固有的推理能力,而是源于缺乏有效的探索管理机制。虽然现有的范式(例如多数投票和 Best-of-N)允许多次尝试,但这些尝试彼此独立。这种轨迹间缺乏通信导致了两个关键的效率低下问题:首先,它造成了重复且冗余的探索,浪费了计算资源;其次,它阻碍了跨轨迹经验共享的可能性,使得模型难以从孤立的经验中综合出全局最优解。这促使我们提出了一种轨迹级递归智能体框架。该模型并非每次尝试都从零开始,而是将之前的轨迹显式地压缩成一个包含已验证信息的综合经验和一个未完成分支的详细枚举。通过将这些反馈融入到 K 次顺序执行中,它可以系统地解决我们在分析中发现的规划和上下文问题。
4.Method: Re-TRAC Framework
Re-TRAC(Recursive TRAjectory Compression)是一个迭代的轨迹级框架。它利用标准化的压缩规范来总结之前的尝试,并将这些上下文信息传递到后续的迭代中。这种机制确保每次迭代都高效且受益于之前的经验。通过不断扩展已知的搜索空间,Re-TRAC 有效地扩大了计划覆盖范围,减少了冗余探索,并避免了陷入死胡同。
4.1 Trajectory Compression as a Structured State Representation
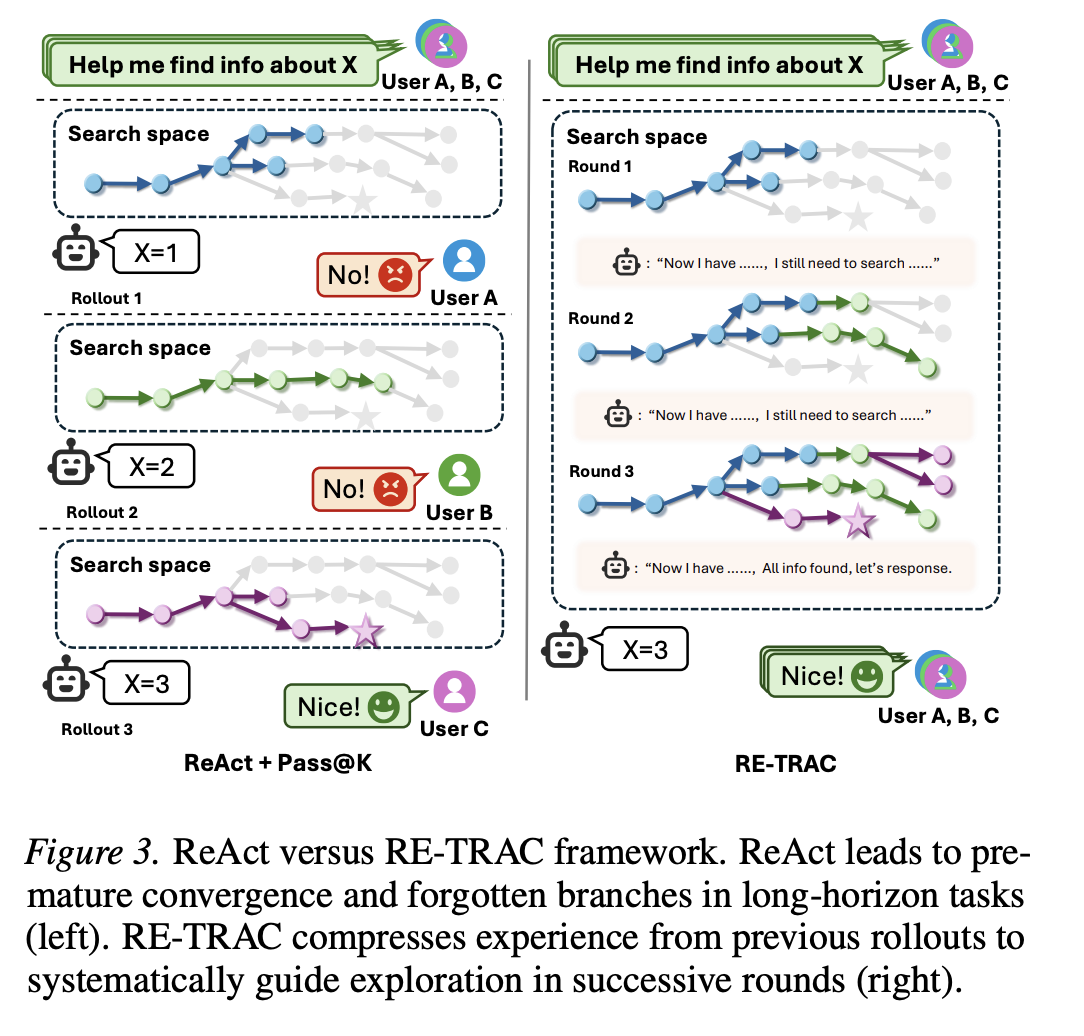
图 3 对比了标准的 ReAct 范式(左)和我们的 Re-TRAC 框架(右)。在 ReAct 中,每次执行都是从原始 query 开始的线性链。较长的上下文会导致“不完整的分支探索”:随着 token 数量的增加,早期计划的可执行性降低,智能体经常会丢失早期观察中嵌入的关键线索。如左图所示,智能体可能会枚举出多个候选分支,但最终未能逐一执行,导致探索覆盖不完整。
Re-TRAC 通过轨迹压缩解决这些问题(见图 4)。每次 rollout 后,轨迹 被提炼成结构化的状态表示 。根据固定的压缩规范 ,状态会迭代更新:
对于深度研究任务,我们通过三个互补的方面来定义 ,从而为智能体提供全面的状态表示:
- Answer & Analytical Conclusions:此维度记录了最有力的部分答案,并存储了轨迹中的关键推论。中间结论被保留下来,作为后续推理的可重用锚点。
- Evidence Base & Source Verification:此维度记录观察到的证据及其来源,追踪参考了哪些资料来源,并标记哪些说法已得到验证。这有助于避免重复调用工具和进行重复检查。
- Uncertainties & Exploration Trace:此维度记录尚未解决的问题,包括开放的假设和候选分支,以及失败的尝试和已放弃的方向。它有助于模型为下一次部署寻找未探索的搜索空间。
这种结构化状态被添加到后续 rollout 的输入中,确保 Agent 在每次新的尝试开始时都清楚地了解哪些内容已验证,哪些内容仍未解决,以及应该将探索重点放在哪里。
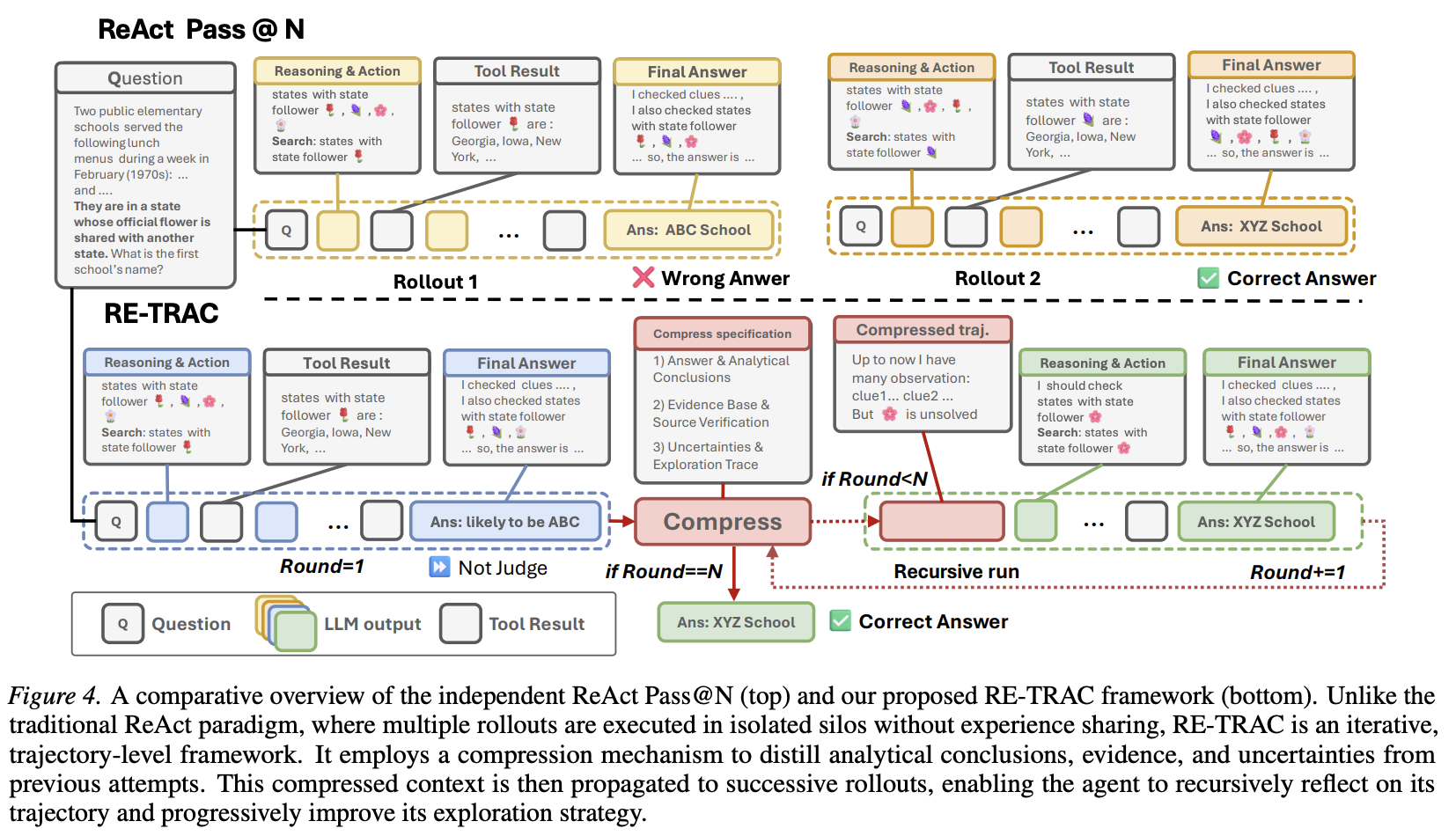
4.2 Recursive Execution with Structured State Representation
Re-TRAC 的设计本身就是递归的,这个过程可以持续多轮。初始 rollout 的功能与标准的 ReAct 执行类似,因此也存在同样的局限性,例如忽略早期规划的分支。
状态表示起到引导搜索更新的作用。它过滤掉不必要的底层追踪细节,避免占用上下文信息。至关重要的是,状态能够防止探索陷入单一路径。它明确地保留了多个未解决的候选路径和可执行选项。这为后续的迭代保持了分支的多样性。这种在聚焦引导和开放分支之间的平衡,支持了递归过程中可控的多样性。因此,智能体能够在保持效率的同时,逐步扩展搜索空间覆盖范围。
这种递归方法具有两大优势。首先,它提高了覆盖率。未完成的分支会被显式地保留,并在后续的 rollout 中执行。其次,它减少了冗余。该模型避免了对已验证的事实重复调用工具。第一轮中遗漏的分支会被记录在状态中,并在下一轮中直接进行探索。相比之下,独立的 ReAct 轮次往往会浪费资源重新探索同一路径。经验表明,这种紧凑性能够提高 token 使用效率和工具调用次数(参见 5.3 节)。
4.3 Application to Frontier Models
Re-TRAC 是一种无需训练的提示策略。它直接应用于推理过程中的前沿模型,无需微调。执行过程非常简单:
首先,我们定义一个 Deep Research Query,并设置最大轮数限制 N(默认为 8)。在初始轮次中,模型利用标准的 ReAct 框架生成完整的轨迹。然后,我们使用一个专门设计的提示(参见 C.3.1 节)来压缩该轨迹,该提示旨在提取结构化状态表示。压缩后的状态将作为下一轮的输入。具体来说,它作为初始用户消息,紧随系统提示之后。之后,模型将执行另一个 ReAct 循环来回答问题,并在此基础上构建之前的状态。此过程递归重复,直到达到轮数限制 N。最后一轮生成的答案将作为 Re-TRAC 的最终输出。
在第 5.3 节中,我们以标准基准测试其性能,包括单次运行、Best-of-N、多数投票和加权投票。
4.4 Training Small Models for Re-TRAC
后续 5.2 节的实验表明,不同规模的深度研究 Agent (从229B到685B不等)都能从 Re-TRAC 工作流程中获益。这启发我们去探索,如果一个小型边缘模型也配备了 Re-TRAC 工作流程,它是否也能达到具有竞争力的性能。
为了研究这一点,我们从 GLM-4.7 的 Re-TRAC 轨迹中蒸馏出 Qwen3-4B-Instruct 和 Tongyi-DeepResearch-30B-A3B。
为了获得用于训练的原始提示,我们首先参考 InfoAgent,通过基于实体树的方法构建大量问答对。具体来说,我们从维基百科收集大量实体作为树的根节点。然后,对于每个实体,我们递归地搜索其相关的实体作为子节点,直到树增长到预定义的深度。相邻节点之间的边表示两个实体之间的关系。我们通过选择从根节点到叶节点的路径并将边转换为子问题来合成问题。为了增加问题的难度,我们还使用 o3 对子问题进行模糊化。通过此流程,我们总共构建了 33,000 个问答对。然后,我们收集了 GLM-4.7 在这些合成问题上的 Re-TRAC(4 轮)轨迹,过滤后得到 104,000 个训练样本,这些样本用于通过 SFT 训练我们的 RE-TRAC-4B 和 RE-TRAC-30B-A3B 模型。详细信息请参见 B 部分。
5.Experiments